


A Microsoft recentemente apresentou seu mais novo modelo de inteligência artificial (IA) chamado Kosmos-1, que tem um enfoque multimodal. Mas o que isso significa?
Os especialistas em IA acreditam que para alcançar uma IA geral que possa realizar tarefas a nível humano, é necessário adotar um enfoque multimodal, que integra diferentes formas de entrada, como texto, áudio, imagens e vídeo, para simular a percepção humana.
E é isso que o Kosmos-1 faz: ele processa diferentes modos de entrada para realizar análises de imagem, reconhecimento de texto visual, resolver acertos visuais, passar por testes de coeficiente intelectual visual e entender instruções em linguagem natural.
Durante o treinamento, a Microsoft utilizou dados da web para avaliar as habilidades de Kosmos-1 em diferentes testes, incluindo compreensão e geração de linguagem, classificação de texto, descrição de imagens, resposta a perguntas visuais e classificação de imagens sem treinamento prévio. Em muitos desses testes, o Kosmos-1 superou modelos de IA de ponta.

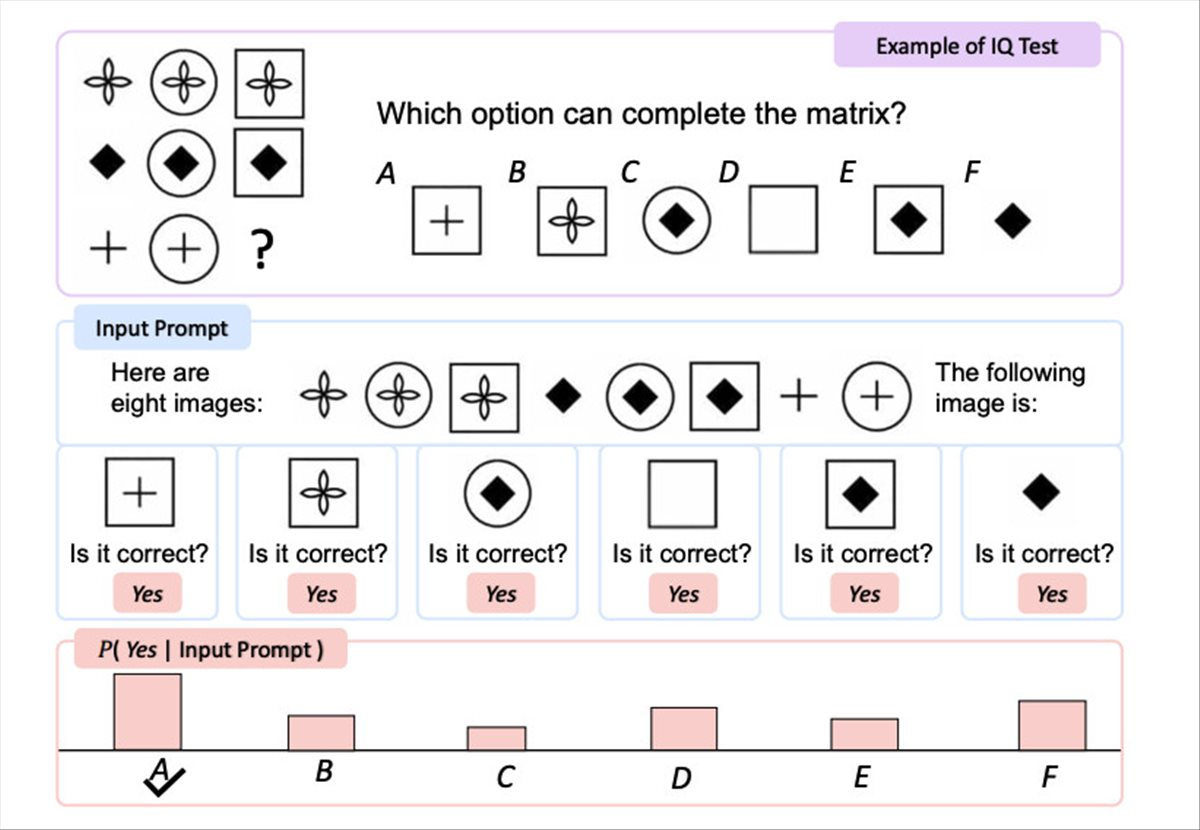
Um aspecto interessante do Kosmos-1 é o seu desempenho na famosa prova de racioncínio progressivo de Raven, que mede o coeficiente intelectual visual.
Nesta prova, Kosmos-1 só respondeu corretamente a uma pergunta 22% do tempo (26% com ajuste fino), mas superou o acaso (17%) na prova de coeficiente intelectual visual de Raven.
Embora o Kosmos-1 represente apenas os primeiros passos no domínio multimodal, é fácil imaginar futuras otimizações que possam trazer resultados ainda mais significativos, permitindo que os modelos de IA percebam qualquer forma de mídia e atuem sobre elas. E isso é um passo importante para alcançar uma IA geral que possa realizar tarefas a nível humano.




